[ad_1]
Apache Spark and Hadoop, Microsoft Power BI, Jupyter Notebook and Alteryx are among the top data science tools for finding business insights. Compare their features, pros and cons.
While data has its benefits, such as enabling businesses to better understand their customers and financial health, it’s a complicated science. It isn’t enough to simply capture your data. You must clean, process, analyze and visualize it to glean any insights. This is where data science tools and software make all the difference.
However, there are many tools available for every stage of data science, from analysis to visualization. Selecting the tools that are best for your organization will require some digging.
Jump to:
Top data science software comparison
Microsoft Power BI: Best for visualizations and business intelligence
![]()
Microsoft Power BI is a powerhouse tool for visualizing and sharing data insights. It’s a self-service tool, which means anyone within an organization can have easy access to the data. The platform enables organizations to compile all of their data in one place and develop simple, intuitive visuals.
Users of Microsoft Power BI can also ask questions in plain language about their data to receive instant insights. This is a great feature for those with very little data science know-how.
As a bonus, Microsoft Power BI is also highly collaborative, making it a great choice for larger organizations. For example, users can collaborate on data reports and use other Microsoft Office tools for sharing and editing.
Pricing
- Free: Power BI in Microsoft Fabric is free.
- Power BI Pro: $10 per user per month.
- Power BI Premium: $20 per user per month.
- Microsoft Fabric: Starts at $4,995 per month for P1 SKU.
Microsoft Power BI features
- Storage: Up to 100TB storage capacity.
- Collaboration: Publish Power BI reports to share and collaborate.
- Multi-geo deployment management: You can deploy content to data centers in regions other than the home region of the Power BI.
- Support advanced AI: This includes text analytics, image detection and automated machine learning (Figure A).
Pros
- Up to 400GB memory size limit.
- Useful for performing complex tasks.
- Self-service capability.
Cons
- User interface can be improved.
- Infrequently lags.
Why we picked Microsoft Power BI
Our analysis found that Power BI visualization options and interactive features allow users to create engaging and insightful visualizations. The integration with other Microsoft products, such as Excel and Azure, gives it access to numerous data sources and analytics tools.
SEE: For more information, read our full Power BI review.
Apache Spark: Best for fast, large-scale data processing
![]()
Apache Spark is an open-source, multi-language engine used for data engineering and data science. It’s known for its speed when handling large amounts of data. The software is capable of analyzing petabytes of data all at once.
Batching is a key feature of Apache Spark, which is compatible with various programming languages, including Python, SQL and R. Many organizations use Apache Spark to process real-time, streaming data due to its speed and agility. Apache Spark is great on its own, or it can be used in conjunction with Apache Hadoop.
Pricing
Apache Spark is an open-source tool available at no cost. However, if you are sourcing the tool from third-party vendors, they may charge you a certain fee.
Features
- SQL analytics: Perform quick, distributed ANSI SQL queries to generate dashboards and ad-hoc reporting.
- Data science at scale: Enables users to perform exploratory data analysis on petabyte-scale data without downsampling.
- Integrations: Integrates with several third-party services, including TensorFlow, Pandas, Power BI and more.
- Batch/streaming data: Allows you to unify the processing of your data in batches and real-time streaming, with the option to use your languages of choice such as Python, SQL, Scala, Java or R (Figure B).
Pros
- Has over 2,000 contributors.
- Works with both structured and unstructured data.
- Includes advanced analytics.
- Boasts fast processing speed.
Cons
- Has limited real-time processing.
- Users report that they experience small file issues.
Why we picked Apache Spark
Its compatibility with multiple programming languages makes it a popular choice among data scientists, and its ability to analyze massive amounts of data all at once makes it a valuable tool for organizations dealing with real-time, streaming data.
SEE: See how Apache Spark compares to Hadoop.
Jupyter Notebook: Best for interactive data analysis and visualization
![]()
Jupyter Notebook is an open-source browser application made for sharing code and data visualizations with others. It’s also used by data scientists to visualize, test and edit their computations. Users can simply input their code using blocks and execute it. This is helpful for quickly finding mistakes or making edits.
Pricing
Jupyter Notebook is a free open-source tool.
Jupyter Notebook features
- Multi-language support: Supports over 40 languages, including Python, R, Julia and Scala.
- Big data integration: Allows you to leverage big data tools such as Apache Spark, Python, R and Scala.
- Share notebooks: Users can share Notebooks with others using email, Dropbox, GitHub and the Jupyter Notebook Viewer.
- Supports centralized deployment: Can be deployed to users across your organization on centralized infrastructure on- or off-site.
- Web-based interactive development environment: Enables users to configure and arrange workflows in data science, machine learning, scientific computing and computational journalism (Figure C).
Pros
- Supports containers such as Docker and Kubernetes.
- Boasts ease-of-use for visualization and code presentation.
- Users praise the tool for its adaptability capability.
Cons
- Some users report that the software infrequently lags when working with large datasets or carrying out complex calculations.
- Users report difficulty in managing the version control of large projects.
Why we picked Jupyter Notebook
The ability to easily share code and visualizations makes it a valuable tool for team collaboration and communication, plus its support for multiple programming languages and diverse output formats makes it a versatile tool for data science projects.
SEE: Explore our in-depth comparison of Jupyter Notebook and PyCharm.
RapidMiner: Best for the entire data analytics process
![]()
RapidMiner is a robust data science platform, enabling organizations to take control over the entire data analytics process. RapidMiner starts by offering data engineering, which provides tools for acquiring and preparing data for analysis. The platform also offers tools specifically for model building and data visualization.
RapidMiner delivers a no-code AI app-building feature to help data scientists quickly visualize data on behalf of stakeholders. RapidMiner states that, thanks to the platform’s integration with JupyterLab and other key features, it’s the perfect solution for both novices and data science experts.
Pricing
RapidMiner doesn’t advertise pricing on its website. It encourages users to request quotes by filling out a form on its pricing page. Publicly available data shows that RapidMiner AI Hub’s pay-as-you-go plan starts at $0.80 per hour and may cost significantly more depending on your instance type.
RapidMiner features
- Automated data science: Offers end-to-end automation and augmentation to boost productivity.
- Hybrid cloud deployment: Enables you to leverage the capabilities of the cloud and security of on-premise.
- Coding: Code-based data science that enables data scientists to create custom solutions using code.
- Visual analytics workflow: Offers a drag-and-drop visual interface (Figure D).
Pros
- Has over a million global users.
- Enables analytics teams to access, load and evaluate different data types, such as texts, images and audio tracks.
- Includes extensive learning materials available online.
Cons
- Steep learning curve for new and inexperienced users.
- Performance and speed issues; some users report the platform slows down when processing complex datasets.
Why we picked RapidMiner
Its drag-and-drop interface and automated processes make it accessible for users of all skill levels, and its wide range of pre-built tools and integrations with other platforms make it a versatile tool for handling complex data science tasks.
SEE: RapidMiner is also considered a top choice for predictive analytics.
Apache Hadoop: Best for distributed data processing
![]()
Although we’ve already mentioned one Apache solution, Hadoop also deserves a spot on our list. Apache Hadoop, an open-source platform, includes several modules, such as Apache Spark, and simplifies the process of storing and processing large amounts of data.
Apache Hadoop breaks large datasets into smaller workloads across various nodes and then processes these workloads at the same time, improving processing speed. The various nodes make up what is known as a Hadoop cluster. Though Apache Hadoop lacks visualization tools, you can use third-party software to visualize your Hadoop data.
Pricing
Apache Hadoop is an open-source tool available for free. If you are sourcing the tool from third-party vendors, they may charge you a certain fee.
Apache Hadoop features
- Provides fault tolerance: By replicating data across multiple nodes, it ensures that data is not lost in the event of machine failures.
- High availability: Fault tolerance provides high availability in the Hadoop cluster.
- Integration with other Apache services: It integrates with other tools like Apache Spark, Apache Flink and Apache Storm (Figure E).
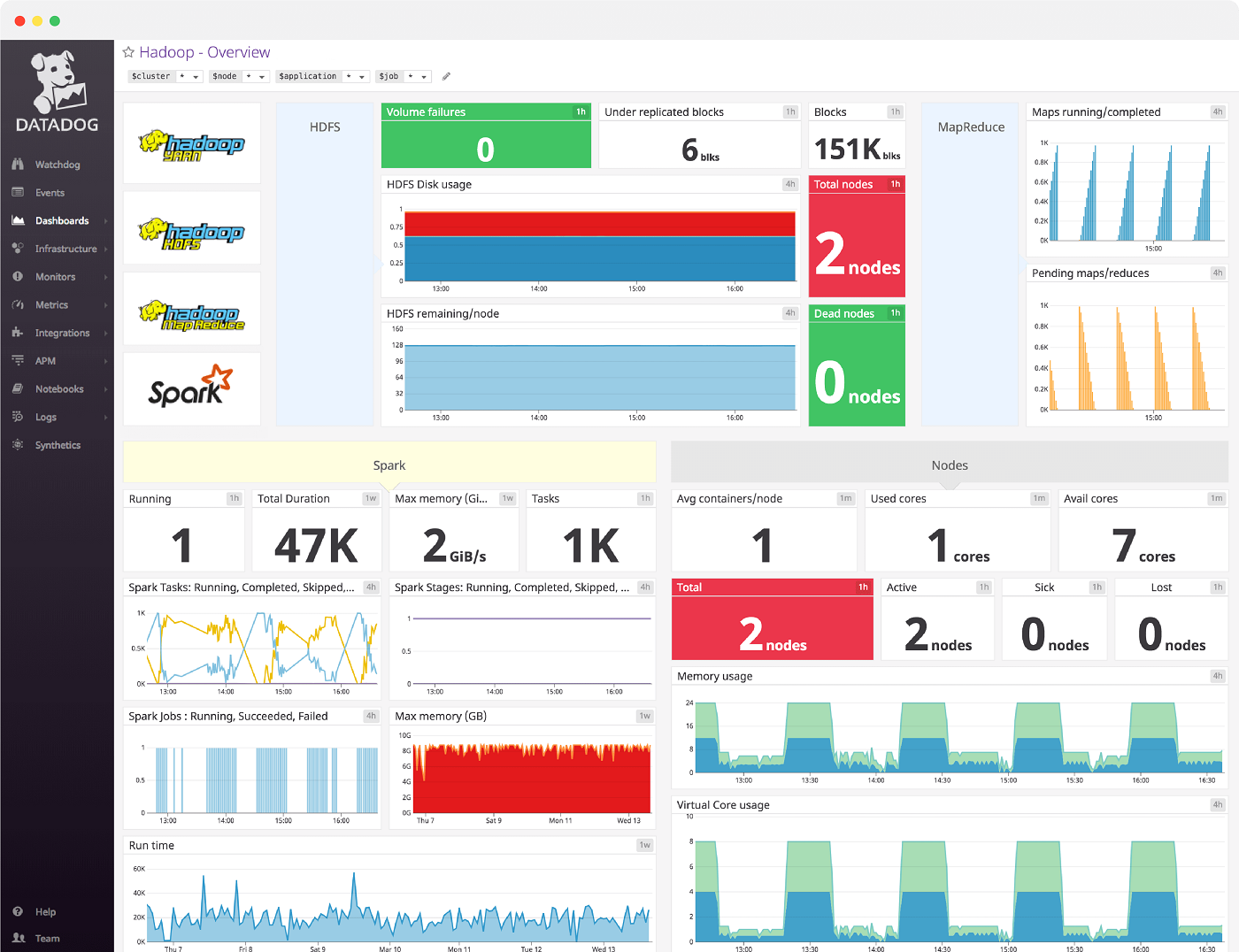
Pros
- High availability.
- Faster data processing.
- Highly scalable.
Cons
- Users report the tool is slower than other querying engines.
- Steep learning curve.
Why we picked Apache Hadoop
Apache Hadoop’s ability to handle large-scale data processing and storage makes it valuable. Hadoop’s fault-tolerant nature ensures that data is protected and available even in the event of machine failures.
SEE: For more information, check out our Apache Hadoop cheat sheet.
Alteryx: Best for offering data analytics access to all
![]()
Everyone within an organization should have access to the data insights they need to make informed decisions. Alteryx is an automated analytics platform that enables self-service access to data insights for all members of an organization.
Alteryx offers various tools for all stages of the data science process, including data transformation, analysis and visualization. The platform comes with hundreds of code-free automation components organizations can use to build their own data analytics workflow.
Pricing
Alteryx prices vary based on the product you choose, the number of users in your team and the length of your contract.
Designer Cloud:
- Starter: $80 per user per month with an annual contract. No minimum license count.
- Professional: $4,950 per user per year. Minimum three user licenses.
- Enterprise: Custom quotes. Minimum seven user licenses.
Designer Desktop: Costs about $5,195.
According to information on the AWS marketplace, Alteryx Designer/Server, which bundles one Designer user license and one Server, costs $84,170 for 12 months and $252,510 for 36 months.
Alteryx features
- Connectors: It integrates with 80+ data sources and outputs to over 70 different tools.
- Role-based access control: Admins can set permissions and privileges to enable access to authorized users.
- Extract insight easily: Monitor trends and patterns with low-code, no-code spatial and prescriptive analytics.
- Drag-and-drop UI: Offers 300+ drag & drop analytics automation tools (Figure F).
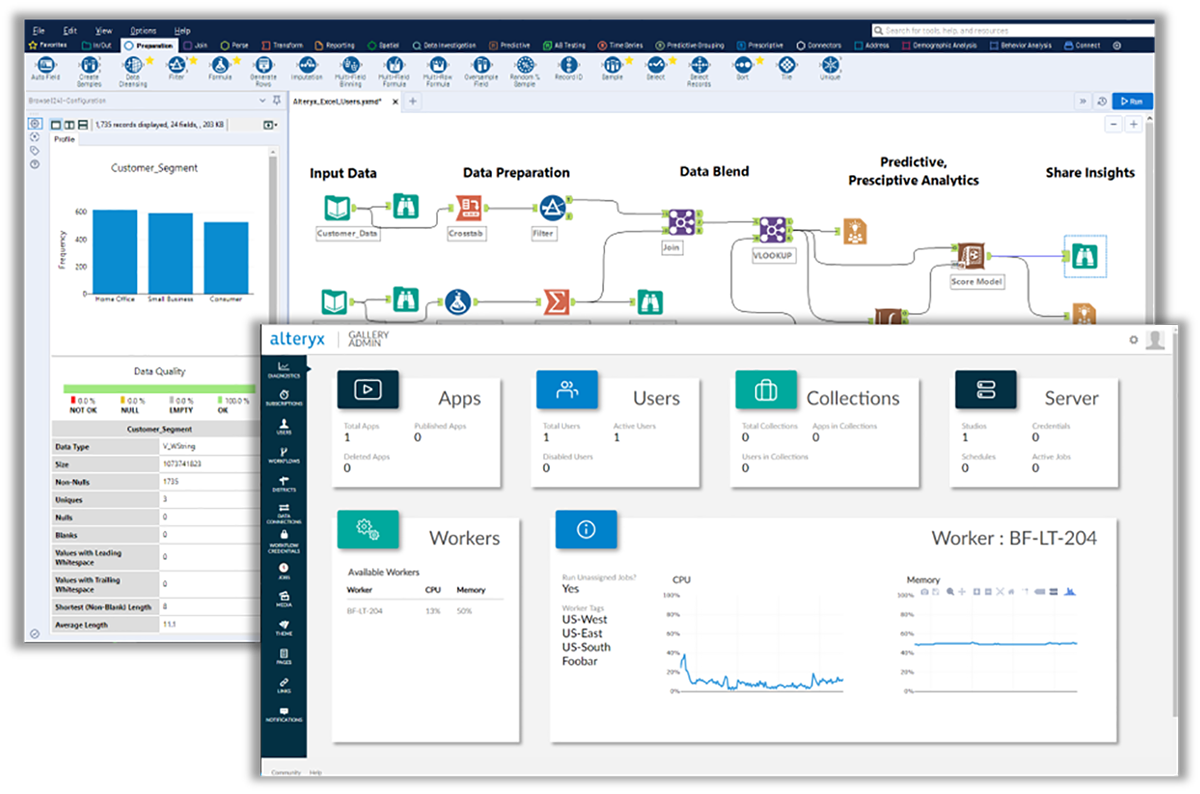
Pros
- 30-day free trial.
- Excellent support from Alteryx.
- Easy to set up.
Cons
- Users report the integration capability can be improved.
- Data visualization capability can be improved.
Why we picked Alteryx
We ranked Alteryx as one of the best data science tools for its ease of use and comprehensive data preparation and blending features. Its visual interface and drag-and-drop workflow builder make it accessible to users with varying programming experiences.
SEE: For more information, read our in-depth Alteryx review.
Python: Best for every stage of data science
![]()
Python is one of the most popular programming languages used for data analytics. It’s simple to learn and widely accepted by many data analytics platforms available on the market today. Python is used for a wide range of tasks throughout the data science lifecycle. For example, it can be used in data mining, processing and visualization.
Python is far from the only programming language out there. Other options include SQL, R, Scala, Julia and C. However, it is often chosen by data scientists for its flexibility as well as the size of its online community. And being an open-source tool, this is critical.
Pricing
Python is a free, open-source programming language; you can download it and its frameworks and libraries at no charge.
Python features
- Standard library: It has a large standard library that includes modules and functions for different tasks.
- Object-oriented and procedure-oriented: It supports object-oriented language and concepts of classes and object encapsulation.
- Cross-platform language: Python can run on different platforms, such as Windows, Linux, UNIX and Mac.
- Support for graphical user interface: Users can interact with the software using GUI (Figure G).
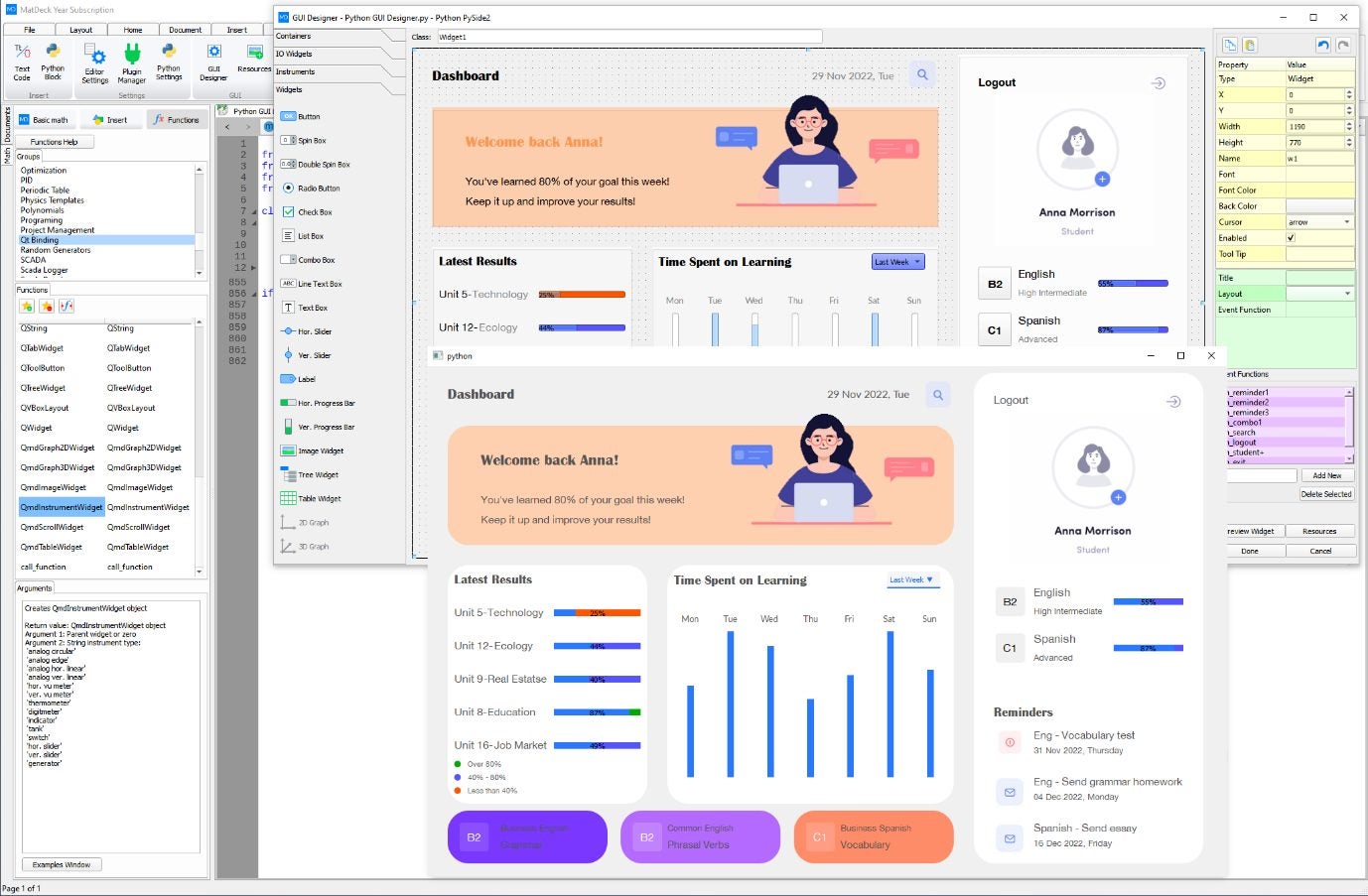
Pros
- Extensive library.
- Large community.
- High-level language, making it easy for beginners to understand.
Cons
- Can be slower than other languages like Java and C when running computation-heavy tasks.
- Heavy memory usage.
Why we picked Python
Python is widely considered one of the best programming languages for data science due to its versatility and extensive ecosystem of libraries and frameworks.
SEE: For more information, explore our Python cheat sheet.
KNIME: Best for designing custom data workflows
![]()
The KNIME Analytics Platform is an open-source solution that provides everything from data integration to data visualization. One feature that’s worth highlighting is KNIME’s ability to be customized to fit your specific needs. Using visual programming, the platform can be customized through drag-and-drop functionality without the need for code.
KNIME also features access to a wide range of extensions to further customize the platform. For example, users can benefit from network mining, text processing and productivity tools.
Pricing
- Personal plan: Free of charge.
- Team plan: Starts at $285 per month.
- Basic, standard and enterprise plan pricing is available on request.
KNIME features
- Integration authentication: Support integration authentication with corporate LDAP and Active Directory setups and single sign-on via OAuth, OIDC and SAML.
- User credential management: Offers advanced user role and permission management.
- Integration: Has 300+ connectors to data sources.
- Collaboration: Ability for users to share and collaborate on workflows and components (Figure H).

Pros
- Collaboration on workflows in public spaces.
- Community support.
- Excellent user interface.
Cons
- Team plan storage is limited to 30GB.
- Users report slow performance when using the tool.
Why we picked KNIME
KNIME’s integration with various data sources and its support for scripting languages allow for flexible and customizable workflows.
SEE: Check out our in-depth comparison of KNIME versus Alteryx.
How do I choose the best data science software for my business?
The best data science software for you depends on your business needs, data expert capabilities and data complexity. In order to select the best tool for your use cases, there are several factors to consider, including the technical knowledge of your team, your data science goals, the complexity of your data and your budget.
Additionally, review at least three different data science software that align with your business needs, test run them by signing up for a free trial and request for a product demo before selecting the one that best serves your business purposes.
Review methodology
We collected primary data about each tool from the vendor’s website, including features, use cases and pricing information. We also reviewed user experience feedback from independent websites like Gartner to learn about each data science software’s usability, ease of use and customer satisfaction.
[ad_2]